Neural networks are a fascinating field of machine learning. Let’s see how to find the best number of neurons of a neural network for our dataset.

Online courses and lessons about data science, machine learning and artificial intelligence
Online courses and lessons about data science, machine learning and artificial intelligence
Neural networks are a fascinating field of machine learning. Let’s see how to find the best number of neurons of a neural network for our dataset.

The first thing I have learned as a data scientist is that feature selection is one of the most important steps of a machine learning pipeline. Fortunately, some models may help us accomplish this goal by giving us their own interpretation of feature importance. One of such models is the Lasso regression.

In the machine learning world, data scientists are often told to train a supervised model on a large training dataset and test it on a smaller amount of data. The reason why training dataset is always chosen larger than the test one is that somebody says that the larger the data used for training, the better the model learns.

Language detection (or identification) is a fascinating branch of Natural Language Processing. Its goal is to create a model that is able to detect the language a text is written in. Data Scientists usually employ neural network models to accomplish such a goal. In this article, I show how to create a simple language detection model in Python using a Naive Bayes model.

I’m glad to introduce my new free online workshop about feature importance in machine learning. In this workshop, feature importance in supervised machine learning is presented both in theory and in practice using Python programming language and its powerful scikit-learn library.

Feature selection is probably the most important part of machine learning, as well as hyperparameter tuning. How can we select the right …

Feature selection has always been a great task in machine learning. According to my experience, I can surely say that feature selection is much more important than model selection itself.
Professional data scientists know that data must be prepared before feeding any model with it. Data pre-processing is probably the most important part of a machine learning pipeline and its importance is sometimes underestimated.

Every measure must be followed by an error estimate. There’s no chance to avoid this. If I tell you “I’m 1,93 …
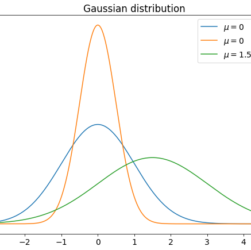
Statistics is a must-have skill in a Data Scientist’s CV, so there are concepts and topics that must be known in advance if somebody wants to work with data and machine learning models. Probability distributions are a must-have tool. Let’s see the most important ones to know for a Data Scientist.